House Prices

Ask a home buyer to describe their dream house, and they probably won't begin with the height of the basement ceiling or the proximity to an east-west railroad. But this playground competition's dataset proves that much more influences price negotiations than the number of bedrooms or a white-picket fence.
Published on January 01, 2019 by Udbhav Pangotra
pandas numpy plotly matplotlib
21 min READ
Ask a home buyer to describe their dream house, and they probably won’t begin with the height of the basement ceiling or the proximity to an east-west railroad. But this playground competition’s dataset proves that much more influences price negotiations than the number of bedrooms or a white-picket fence.
With 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa, this competition challenges you to predict the final price of each home.
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
/kaggle/input/house-prices/__output__.json
/kaggle/input/house-prices/__notebook__.ipynb
/kaggle/input/house-prices/submission.csv
/kaggle/input/house-prices/__results__.html
/kaggle/input/house-prices/custom.css
/kaggle/input/house-prices/__resultx__.html
/kaggle/input/house-prices/__results___files/__results___13_1.png
/kaggle/input/house-prices/__results___files/__results___5_1.png
/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv
/kaggle/input/house-prices-advanced-regression-techniques/test.csv
/kaggle/input/house-prices-advanced-regression-techniques/data_description.txt
/kaggle/input/house-prices-advanced-regression-techniques/train.csv
from datetime import datetime
from scipy.stats import skew # for some statistics
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
from sklearn.linear_model import ElasticNetCV, LassoCV, RidgeCV
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import mean_squared_error
from mlxtend.regressor import StackingCVRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
#import data
dat_train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv')
dat_test = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv')
train = dat_train
test = dat_test
train.drop(['Id'], axis=1, inplace=True)
test.drop(['Id'], axis=1, inplace=True)
train['SalePrice'].hist(bins = 40)
<matplotlib.axes._subplots.AxesSubplot at 0x7faf6ea4cdd8>
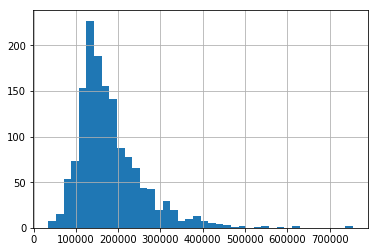
train = train[train.GrLivArea < 4500]
train.reset_index(drop=True, inplace=True)
train["SalePrice"] = np.log1p(train["SalePrice"])
y = train['SalePrice'].reset_index(drop=True)
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
This is separate from the ipykernel package so we can avoid doing imports until
train_features = train.drop(['SalePrice'], axis=1)
test_features = test
features = pd.concat([train_features, test_features]).reset_index(drop=True)
features.shape
(2917, 79)
features['MSSubClass'] = features['MSSubClass'].apply(str)
features['YrSold'] = features['YrSold'].astype(str)
features['MoSold'] = features['MoSold'].astype(str)
## Filling these columns With most suitable value for these columns
features['Functional'] = features['Functional'].fillna('Typ')
features['Electrical'] = features['Electrical'].fillna("SBrkr")
features['KitchenQual'] = features['KitchenQual'].fillna("TA")
features["PoolQC"] = features["PoolQC"].fillna("None")
## Filling these with MODE , i.e. , the most frequent value in these columns .
features['Exterior1st'] = features['Exterior1st'].fillna(features['Exterior1st'].mode()[0])
features['Exterior2nd'] = features['Exterior2nd'].fillna(features['Exterior2nd'].mode()[0])
features['SaleType'] = features['SaleType'].fillna(features['SaleType'].mode()[0])
print(df_test.shape)
print(df_train.shape)
print(features.shape)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-11-768610f0e8ae> in <module>
----> 1 print(df_test.shape)
2 print(df_train.shape)
3 print(features.shape)
NameError: name 'df_test' is not defined
features.head()
| MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | LotConfig | ... | ScreenPorch | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | Inside | ... | 0 | 0 | None | NaN | NaN | 0 | 2 | 2008 | WD | Normal |
| 1 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | FR2 | ... | 0 | 0 | None | NaN | NaN | 0 | 5 | 2007 | WD | Normal |
| 2 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | Inside | ... | 0 | 0 | None | NaN | NaN | 0 | 9 | 2008 | WD | Normal |
| 3 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | Corner | ... | 0 | 0 | None | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml |
| 4 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | FR2 | ... | 0 | 0 | None | NaN | NaN | 0 | 12 | 2008 | WD | Normal |
5 rows × 79 columns
features['BsmtFinSF2'].describe()
count 2916.000000
mean 49.616255
std 169.258662
min 0.000000
25% 0.000000
50% 0.000000
75% 0.000000
max 1526.000000
Name: BsmtFinSF2, dtype: float64
sns.boxplot(features['TotalBsmtSF'])
<matplotlib.axes._subplots.AxesSubplot at 0x7faf6e952dd8>
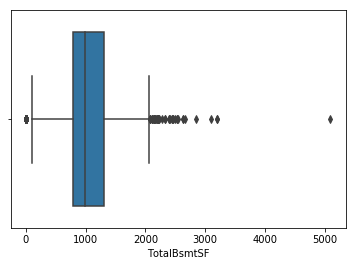
features['LotFrontage'].quantile(.95)
107.0
features['LotFrontage'].quantile(0.05)
32.0
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
features[col] = features[col].fillna(0)
for col in ['GarageType', 'GarageFinish', 'GarageQual', 'GarageCond']:
features[col] = features[col].fillna('None')
### Same with basement
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
features[col] = features[col].fillna('None')
features['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
objects = []
for i in features.columns:
if features[i].dtype == object:
objects.append(i)
features.update(features[objects].fillna('None'))
print(objects)
['MSSubClass', 'MSZoning', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', 'KitchenQual', 'Functional', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence', 'MiscFeature', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition']
features['LotFrontage'] = features.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
numeric_dtypes = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numerics = []
for i in features.columns:
if features[i].dtype in numeric_dtypes:
numerics.append(i)
features.update(features[numerics].fillna(0))
numerics[1:10]
['LotArea',
'OverallQual',
'OverallCond',
'YearBuilt',
'YearRemodAdd',
'MasVnrArea',
'BsmtFinSF1',
'BsmtFinSF2',
'BsmtUnfSF']
numeric_dtypes = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numerics2 = []
for i in features.columns:
if features[i].dtype in numeric_dtypes:
numerics2.append(i)
skew_features = features[numerics2].apply(lambda x: skew(x)).sort_values(ascending=False)
high_skew = skew_features[skew_features > 0.5]
skew_index = high_skew.index
for i in skew_index:
features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
features = features.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
# Adding new features . Make sure that you understand this.
features['YrBltAndRemod']=features['YearBuilt']+features['YearRemodAdd']
features['TotalSF']=features['TotalBsmtSF'] + features['1stFlrSF'] + features['2ndFlrSF']
features['Total_sqr_footage'] = (features['BsmtFinSF1'] + features['BsmtFinSF2'] +
features['1stFlrSF'] + features['2ndFlrSF'])
features['Total_Bathrooms'] = (features['FullBath'] + (0.5 * features['HalfBath']) +
features['BsmtFullBath'] + (0.5 * features['BsmtHalfBath']))
features['Total_porch_sf'] = (features['OpenPorchSF'] + features['3SsnPorch'] +
features['EnclosedPorch'] + features['ScreenPorch'] +
features['WoodDeckSF'])
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
features['hasgarage'] = features['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
features['hasbsmt'] = features['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
features['hasfireplace'] = features['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
features.describe()
| LotFrontage | LotArea | OverallQual | OverallCond | YearBuilt | YearRemodAdd | MasVnrArea | BsmtFinSF1 | BsmtFinSF2 | BsmtUnfSF | ... | YrBltAndRemod | TotalSF | Total_sqr_footage | Total_Bathrooms | Total_porch_sf | haspool | has2ndfloor | hasgarage | hasbsmt | hasfireplace | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | ... | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.000000 | 2917.00000 | 2917.000000 | 2917.000000 | 2917.000000 |
| mean | 18.685329 | 13.973272 | 6.086390 | 4.369939 | 1971.287967 | 1984.248200 | 8.054900 | 88.033861 | 1.161039 | 60.080829 | ... | 3955.536167 | 908.955850 | 498.413394 | 2.218330 | 31.140703 | 0.004114 | 0.42818 | 0.945835 | 0.972917 | 0.513198 |
| std | 3.639198 | 1.123677 | 1.406704 | 0.761596 | 30.286991 | 20.892257 | 10.988433 | 77.819542 | 3.248349 | 32.694382 | ... | 46.131676 | 510.967728 | 508.846721 | 0.812670 | 25.089251 | 0.064018 | 0.49490 | 0.226382 | 0.162352 | 0.499911 |
| min | 8.726308 | 10.003399 | 1.000000 | 0.926401 | 1872.000000 | 1950.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 3830.000000 | 5.203415 | 5.203415 | 0.993440 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 17.249650 | 13.562643 | 5.000000 | 3.991517 | 1953.000000 | 1965.000000 | 0.000000 | 0.000000 | 0.000000 | 37.840141 | ... | 3920.000000 | 521.539956 | 108.933226 | 1.534418 | 10.276092 | 0.000000 | 0.00000 | 1.000000 | 1.000000 | 0.000000 |
| 50% | 19.011798 | 14.083060 | 6.000000 | 3.991517 | 1973.000000 | 1993.000000 | 0.000000 | 90.540803 | 0.000000 | 59.438781 | ... | 3954.000000 | 743.714848 | 205.275795 | 2.000000 | 27.547834 | 0.000000 | 0.00000 | 1.000000 | 1.000000 | 1.000000 |
| 75% | 20.673625 | 14.537687 | 7.000000 | 4.679500 | 2001.000000 | 2004.000000 | 17.820533 | 148.020255 | 0.000000 | 82.076255 | ... | 4002.000000 | 1248.362572 | 900.932407 | 2.534418 | 50.147047 | 0.000000 | 1.00000 | 1.000000 | 1.000000 | 1.000000 |
| max | 47.771471 | 22.152570 | 10.000000 | 6.637669 | 2010.000000 | 2010.000000 | 50.083827 | 494.260105 | 14.384508 | 153.865903 | ... | 4020.000000 | 3598.805774 | 2869.016566 | 7.096649 | 153.099818 | 1.000000 | 1.00000 | 1.000000 | 1.000000 | 1.000000 |
8 rows × 43 columns
features.shape
(2917, 86)
final_features = pd.get_dummies(features).reset_index(drop=True)
final_features.shape
(2917, 333)
X = final_features.iloc[:len(y), :]
X_sub = final_features.iloc[len(y):, :]
X.shape, y.shape, X_sub.shape
((1458, 333), (1458,), (1459, 333))
outliers = [30, 88, 462, 631, 1322]
X = X.drop(X.index[outliers])
y = y.drop(y.index[outliers])
overfit = []
for i in X.columns:
counts = X[i].value_counts()
zeros = counts.iloc[0]
if zeros / len(X) * 100 > 99.94:
overfit.append(i)
overfit = list(overfit)
X = X.drop(overfit, axis=1)
X_sub = X_sub.drop(overfit, axis=1)
overfit
['MSSubClass_150']
X.shape, y.shape, X_sub.shape
((1453, 332), (1453,), (1459, 332))
kfolds = KFold(n_splits=10, shuffle=True, random_state=42)
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
def cv_rmse(model, X=X):
rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=kfolds))
return (rmse)
alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5]
alphas2 = [5e-05, 0.0001, 0.0002, 0.0003, 0.0004, 0.0005, 0.0006, 0.0007, 0.0008]
e_alphas = [0.0001, 0.0002, 0.0003, 0.0004, 0.0005, 0.0006, 0.0007]
e_l1ratio = [0.8, 0.85, 0.9, 0.95, 0.99, 1]
ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
lasso = make_pipeline(RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds))
elasticnet = make_pipeline(RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio))
svr = make_pipeline(RobustScaler(), SVR(C= 20, epsilon= 0.008, gamma=0.0003,))
gbr = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05, max_depth=4, max_features='sqrt', min_samples_leaf=15, min_samples_split=10, loss='huber', random_state =42)
lightgbm = LGBMRegressor(objective='regression',
num_leaves=4,
learning_rate=0.01,
n_estimators=5000,
max_bin=200,
bagging_fraction=0.75,
#bagging_freq=5,
#bagging_seed=7,
feature_fraction=0.2,
feature_fraction_seed=7,
verbose=-1,
)
# xgboost = XGBRegressor(learning_rate=0.01,n_estimators=3460,
# max_depth=3, min_child_weight=0,
# gamma=0, subsample=0.7,
# colsample_bytree=0.7,
# nthread=-1,booster='gblinear',
# scale_pos_weight=1, seed=27,
# reg_alpha=0.00006)
# stack_gen = StackingCVRegressor(regressors=(ridge, lasso, elasticnet, gbr, xgboost, lightgbm),
# meta_regressor=xgboost,
# use_features_in_secondary=True)
score = cv_rmse(ridge , X)
print("Ridge: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
score = cv_rmse(lasso , X)
print("LASSO: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
score = cv_rmse(elasticnet)
print("elastic net: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
score = cv_rmse(svr)
print("SVR: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
score = cv_rmse(lightgbm)
print("lightgbm: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
score = cv_rmse(gbr)
print("gbr: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
# score = cv_rmse(xgboost)
# print("xgboost: {:.4f} ({:.4f})\n".format(score.mean(), score.std()), datetime.now(), )
Ridge: 0.1013 (0.0140)
2019-09-30 14:20:57.041899
LASSO: 0.1002 (0.0142)
2019-09-30 14:21:05.534832
elastic net: 0.1002 (0.0143)
2019-09-30 14:21:38.211808
SVR: 0.1016 (0.0130)
2019-09-30 14:21:51.233315
lightgbm: 0.1071 (0.0154)
2019-09-30 14:22:12.573507
gbr: 0.1089 (0.0156)
2019-09-30 14:23:35.038417
# print('stack_gen')
# stack_gen_model = stack_gen.fit(np.array(X), np.array(y))
print('elasticnet')
elastic_model_full_data = elasticnet.fit(X, y)
print('Lasso')
lasso_model_full_data = lasso.fit(X, y)
print('Ridge')
ridge_model_full_data = ridge.fit(X, y)
print('Svr')
svr_model_full_data = svr.fit(X, y)
print('GradientBoosting')
gbr_model_full_data = gbr.fit(X, y)
# print('xgboost')
# xgb_model_full_data = xgboost.fit(X, y)
print('lightgbm')
lgb_model_full_data = lightgbm.fit(X, y)
elasticnet
Lasso
Ridge
Svr
GradientBoosting
lightgbm
def blend_models_predict(X):
return ((0.1 * elastic_model_full_data.predict(X)) + \
(0.1 * lasso_model_full_data.predict(X)) + \
(0.15 * ridge_model_full_data.predict(X)) + \
(0.25 * svr_model_full_data.predict(X)) + \
(0.15 * gbr_model_full_data.predict(X)) + \
# (0.15 * xgb_model_full_data.predict(X)) + \
(0.25 * lgb_model_full_data.predict(X)))
print('RMSE')
print(rmsle(y, blend_models_predict(X)))
RMSE
0.07024352799197298
print('Predict submission')
submission = pd.read_csv("../input/house-prices-advanced-regression-techniques/sample_submission.csv")
submission.iloc[:,1] = (np.expm1(blend_models_predict(X_sub)))
Predict submission
submission.to_csv("submission.csv", index=False)
submission.head()
| Id | SalePrice | |
|---|---|---|
| 0 | 1461 | 121313.839221 |
| 1 | 1462 | 159878.976958 |
| 2 | 1463 | 189666.456458 |
| 3 | 1464 | 200699.874103 |
| 4 | 1465 | 190274.898687 |